 Back to all articles
Back to all articles
Blogs
Developing a RAG System for Scalable Enterprise Search

![]() By Nextbridge Editorial Team
By Nextbridge Editorial Team
The tech world is filled with data-driven enterprises having vast amounts of information, which makes it essential to retrieve efficient documents. Traditional search methods, including keyword-based and SQL queries, often fall short when dealing with larger data volumes. Something similar happened to one of our clients. This article will explore how we implemented the Retrieval-Augmented Generation system to help our client get fast, accurate, and scalable search capabilities.
The Problem
The client was having issues in searching through millions of files including PDFs, Words and Text documents. They were using keywords based search and some SQL based search previously which were not efficient. This led to increased time spent on fetching the useful information from their data.
The Goal
To perform searches in Natural languages.
The Solution
To help our client search through a huge bulk of files and data, we implemented the RAG system using Mistral AI Model.
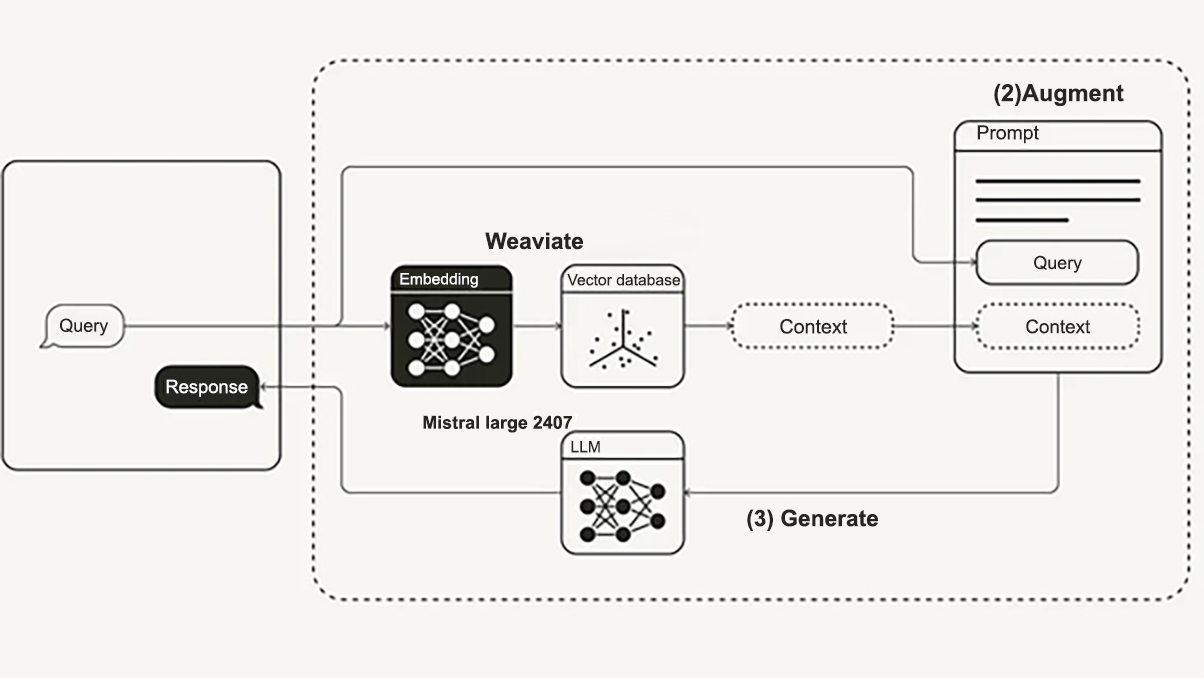
RAG System
We applied the scalable RAG System using Weaviate as a vector database for the embeddings on their local system. It was generated using t2v transformers neural search.
Mistral AI Model
We used the Mistral AI Model (Mistral Large 2407) to search through the files depending upon the query of the client.
Why did we use RAG?
You might be wondering why we opted for a RAG System for Scalable Enterprise Search instead of a model training approach. We chose the RAG approach rather than a full model training approach as it offers more scalable, efficient, and cost-effective solutions for enterprise search. A custom AI model on millions of documents will require comprehensive computational resources to train, continuous return to maintain with new data, and significant fine-tuning efforts to maintain accuracy.
Contrary to this, the RAG takes advantage of a pre-trained language model. This ensures up-to-date and relevant precise reactions to dynamically obtain the most relevant documents with a vector database (Weaviate). This hybrid approach allows for rapid deployment and improves accuracy by grounding reactions in existing enterprise knowledge. Moreover, it provides better adaptability to develop data without returning the entire model.
In short, we chose the RAG model because it
- Enhances factual accuracy: reduces AI hallucinations.
- Handles dynamic knowledge: useful for constantly changing information.
- Optimizes storage: avoids fine-tuning a model on every new dataset.
Implementation Steps:
- Data Extraction and Embeddings Generation
- Fetched text from files.
- Cleaned and normalized the data and prepared it for processing.
- Passed the data to Weaviate using t2v_transformers and generated Embeddings.
- Vector Indexing in Weaviate:
- Setup Weaviate for efficient storage and retrieval.
- Index the embeddings for fast similarity searches.
- Query Processing with RAG:
- Used FastAPI for backend services and query processing.
- Fetched the documents using nearest-neighbour search to get the most relevant documents from Weaviate.
- Passed relevant files to Mistral AI to get the response according to the query.
- Performance Optimization & Deployment:
- Used the Mistral AI Model on Google Cloud (Vertex AI) for high availability and low-latency responses.
Related read: https://nextbridge.com/ai-chatbot-development-challenges-case-study/
The Transformer Architecture
Results
The implementation of the RAG system and the Mistral AI Model increased the recall rate by delivering the following benefits:
Faster Search: Better and faster results as compared to keyword-based SQL Search.
Higher Accuracy: More precise documents as per the given query.
Scalability: The system handled millions of files with ease, supporting real-time queries.
Productivity Boost: Users could search in natural language, which helped them a lot in productivity boost.
Conclusion:
By deploying a RAG-based search solution using Weaviate and Mistral Large 2407, we revolutionized the client's document retrieval process. The solution not only enhanced search effectiveness but also set the stage for future AI-powered automation and knowledge management projects.
Curious how RAG can optimize your business’s data management? Get in touch today!
Don't hire us right away
talk to our experts first,
Share your challenges, & then decide if we're the right fit for you! Talk to Us
Partnerships & Recognition
Commitment to excellence




-
Location
-
 United States
United States
-
 Dubai
Dubai
-
 Pakistan
Pakistan
-
-
Contact us
+1 858 355 9680 511 East John Carpenter Fwy, Suite 500
IRVING, TX 75062, USAFor Business Inquiries:
sales@nextbridge.comFor Job Applications:
careers@nextbridge.com+971-558027173 208, Building A4, Digital Park
Silicon Oasis, Dubai, UAEFor Business Inquiries:
sales@nextbridge.comFor Job Applications:
careers@nextbridge.com042-35315043 / 46 427/428 G-IV Block,
M.A. Johar Town, LahoreFor Business Inquiries:
sales@nextbridge.comFor Job Applications:
careers@nextbridge.com
United States
+1 858 355 9680
511 East John Carpenter Fwy, Suite 500
IRVING, TX 75062, USA
IRVING, TX 75062, USA
For Business Inquiries:
sales@nextbridge.comFor Job Applications:
careers@nextbridge.com
Dubai
+971-558027173
208, Building A4, Digital Park
Silicon Oasis, Dubai, UAE
Silicon Oasis, Dubai, UAE
For Business Inquiries:
sales@nextbridge.comFor Job Applications:
careers@nextbridge.com
Pakistan
042-35315043 / 46
427/428 G-IV Block,
M.A. Johar Town, Lahore
M.A. Johar Town, Lahore
For Business Inquiries:
sales@nextbridge.comFor Job Applications:
careers@nextbridge.com